機械学習入門
機械学習
機械学習とは
機械学習は、コンピュータにデータのパターンを学習させて、役立つ予測や判断をさせる技術の総称で、AI(人工知能)を実現するための手段の一つである。数学的な見方をすると、どんな機械学習モデルも「入力データを受け取り、望ましい出力を返す関数」として表現できる。そして、モデルの学習することは、その関数を決めるパラメータをデータに合うように最適化する作業に他ならない。

機械学習の代表的な枠組みには、人間が正解を教えて学習させる「教師あり学習」、正解を与えずにデータの構造を学習させる「教師なし学習」、試行錯誤を通じて報酬を最大化するように学習させる「強化学習」、近年急速に発展しているニューラルネットワークを用いた「深層学習(ディープラーニング)」がある。それぞれの概要を以下に述べる。
教師あり学習
教師あり学習は、人間が用意した正解データ(ラベル)をもとにモデルを学習する方法。問題ごとに「あらかじめ正解がわかっている入力データ」と「その正解データ」のペアを大量に用意し、それを学習させる。モデルはこれらのデータを読み込んで、入力データから正解を導き出すパターンを学習し、未知のデータに対しても適切な正解を予測できるようになる。
教師あり学習の代表的なタスクには分類問題と回帰問題がある。前者は画像や文章などをカテゴリーごとに分類するタスクで、後者は売上や気温などの連続値を予測するタスクである。

教師なし学習
教師なし学習は、正解データ(ラベル)を持たないデータに対して、その構造やパターンを学習する方法。あらかじめ教える正解がないため、データそのものが持つ特徴を頼りにデータのグループ分けや要約を行う。
教師なし学習の代表的なタスクにはクラスタリングと次元圧縮がある。前者はデータを似たもの同士のグループ(クラスタ)に分類するタスクで、後者は多くの特徴量を持つデータを情報をなるべく失わないように少ない特徴量で表現し直すタスクである。

強化学習
強化学習は、エージェント(学習するプログラム)が環境と呼ばれる世界の中で試行錯誤しながら最適な行動を学習する方法。明確な「正解データ」が与えられない代わりに、エージェントがある状態で何か行動を起こし、その結果として受け取った環境からの累積報酬(ご褒美や罰に相当する評価)が最大となるように学習が進んでいく。エージェントは累積報酬が最大になるような行動を見つけることを目標に、何度も試行錯誤を繰り返す。強化学習の代表的なタスクには囲碁や将棋などのゲームタスクがある。
深層学習
深層学習(ディープラーニング)は、人間の神経細胞(ニューロン)の仕組みを模したニューラルネットワークを何層にも重ねたものを利用して学習する方法。層を深く重ねることでデータから段階的に特徴を抽出し、複雑なパターンも捉えることができる。
深層学習の代表例として、文章を理解して回答を生成する大規模言語モデル(LLM)がある。2025年時点の大規模言語モデルのパラメータ数は10B~1T(百億~1兆)程度のものが多い。
どんな機械学習も「関数」であるという視点
機械学習アルゴリズムはさまざま存在するが、本質的にはどれも「データから最適な関数を自動で見つけ出そうとする試み」だと理解できる。つまり、以下のようなことが言える。
AIは魔法のようなことをしているのではなく、内部ではすべて数式に基づいた計算を行っているに過ぎない。例え最新の深層学習モデルであっても、その内部では膨大な行列演算と非線形変換が何層にも連なっているだけである。難しそうに見える機械学習の理論も、「入力から出力への関数を見つける話だ」と捉えることで、各手法の違いや共通点が見通しやすくなる。
様々な機械学習アルゴリズム
以下、代表的な機械学習アルゴリズムを紹介する。
線形回帰
線形回帰は、入力と出力の関係が線形(直線)で表せると仮定して、その最適な直線(高次元の場合は超平面)をデータから学習する手法である。例えば、身長と体重の関係のように「身長が高いほど体重も重い」という直線的な傾向がある場合、線形回帰を使って身長から体重を予測することができる。
予測値を求める関数は次の式で表される。
ここで、は特徴量(入力データ)、は重み(パラメータ)、は特徴量をまとめた特徴量ベクトルである。
この関数がデータにできるだけ当てはまるように、平均二乗誤差 (MSE)を最小化するように重み(パラメータ)を調整する。
一次元(特徴量が1つ)の単純な線形回帰、つまりの場合の学習は、散布図にプロットしたデータ点に対して最適な直線を引くことに対応する。そして、その直線を使うと、未知のデータが得られたときの予測値を計算できる。
線形回帰はモデルが非常に単純で結果を解釈しやすく、計算も速いため、経済学や社会科学など幅広い分野でデータの傾向をつかむ基本的な方法として利用されている。ただし、非線形なデータや外れ値を含むデータのように、線形回帰ではうまく予測できない場合もある。

ロジスティック回帰
ロジスティック回帰は、名前に「回帰」とあるが分類問題(特に二値問題)に用いられる学習手法である。 例えば、メールが「迷惑メールかどうか」を判定するような、結果が「はい(1)/いいえ(0)」などの二値に分かれる問題に適していて、予測値「迷惑メールである(1)」の確率が求められる。
予測値の確率を求める関数は次の式で表される。
ロジスティック回帰では、線形回帰と同じようにを計算し、シグモイド関数に通して0~1の範囲に収まる確率に変換する。
この関数がデータにできるだけ当てはまるように、交差エントロピー損失が最小になるように重み(パラメータ)を調整する。
一次元(特徴量が1つ)の単純なロジスティック回帰、つまりの場合の学習は、散布図にプロットしたデータ点に対して最適なS字カーブを引くことに対応する。そして、そのS字カーブを使うと、未知のデータが得られたときの予測値の確率を計算できる。
線形回帰はモデルが非常に単純で結果を解釈しやすく、計算も速いため、経済学や社会科学など幅広い分野でデータの傾向をつかむ基本的な方法として利用されている。ただし、非線形なデータや外れ値を含むデータのように、線形回帰ではうまく予測できない場合もある。
線形回帰と同様、モデルが非常に単純で結果を解釈しやすく、計算も速いため、スパムメール検知や疾患の診断など様々な二値分類問題で広く利用されている。ただし、決定境界(分類結果が切り替わる境界)は線形(直線的)になるため、データの分布が複雑に入り組んでいる場合はうまく分類出来ない。

サポートベクトルマシン(SVM)
サポートベクトルマシンは、分類の境界線(決定境界)をできるだけ「余裕(マージン)」をもって引くように学習する分類手法。マージンとは境界線とデータ点との距離のことで、境界線に最も近いデータ点からの距離が最大になるように境界を定める。
線形モデルをベースにした二値分類器という点ではロジスティック回帰と同じだが、サポートベクトルマシンは線形分離可能でないデータに対しても、カーネル関数を用いて高次元空間に写像することで分離できるようにする(カーネルトリック)。

サポートベクトルマシンでは、ロジスティック回帰とは異なり、予測値の確率ではなく予測値を直接求める。予測値を求める関数は次の式で表される。
線形分離可能な場合
線形分離可能でない場合
ナイーブベイズ
ナイーブベイズは、ベイズの定理に基づくシンプルな確率モデルによる分類手法。電子メールのフィルタリングや文章のトピック分類など、自然言語の分類でよく使われた歴史がある。未知のデータに含まれる特徴が各カテゴリに当てはまる確率を、ベイズの定理に基づいて計算し、最も確率の高いカテゴリに分類する。
各カテゴリに属する確率を求める関数は次の式で表される。
決定木
決定木は、学習データに対して「Yes/No」で答えられるような質問を繰り返し、データを枝分かれで分類していくことで予測を行う手法である。その形が木を逆さまにした形に見えるため「決定木」と呼ばれる。ルート(根)からスタートし、「この条件を満たすか?」という質問に対して「Yesなら左の枝、Noなら右の枝」というように条件分岐を繰り返していき、最後に葉と呼ばれる末端に到達したときに予測結果(分類ならラベル、回帰なら予測値)を出力する。データをどう分割するか(次の質問は何にするか)については、不純度(一つのグループに含まれるラベルの種類)が最も減少するように学習する。

条件分岐を繰り返すだけだが、無理やり関数で表現すると次の式で表される。
ここで、は葉(条件分岐によってたどり着いた最終ノード)の識別子で、は葉に対応したラベル(回帰問題なら予測値)を、はが葉の領域に含まれるかどうかを表現している。条件分岐の結果葉にたどり着いた場合、上式は次のようになる。
決定木は、分岐の過程を追えば「どうしてこの結果になったのか」わかるので、仕組みや結果を人間が理解しやすい。ただし、分岐ルールが細かくなりすぎると、一種の丸暗記のようになって新しいデータに対応できなくなる過学習を起こしやすくなってしまう。
ランダムフォレスト
ランダムフォレストは、多数の決定木を組み合わせてより精度の高い予測を行う手法である。一本の決定木だと偏った予測になることがあるが、ランダムフォレストでは複数の決定木それぞれに予測させて、最後に多数決や平均を取ることで、個々の木の弱点を補い合って予測精度を向上させる。

回帰問題では複数の決定木の平均を取るので、次の式で表される。(分類問題の場合はただの多数決なので省略)
ランダムフォレストでは、すべての決定木が同じ結果になってしまわないように、各木を少しずつ異なるデータで学習させるよう工夫している。具体的には、学習データから一部をランダムに選んで各決定木に与えたり、分岐に使う特徴量を決定木ごとにランダムに限定したりします。これによって木ごとに多少異なる癖がつき、多様な決定木の集まり(フォレスト)になる。
複数の決定木の総合力によって、単体の決定木よりも過学習に強く汎用的で精度の高いモデルが得られる。ただし、最終的な判断が多数の木の投票で決まるため、「なぜその結果になったか」の説明は単一の決定木に比べて難しくなる場合がある。
GBDT(勾配ブースティング木)
GBDTは、複数の決定木を直列につなげて徐々にモデルを改善していく手法である。二本目以降の決定木では、前の決定木がうまく予測できなかった部分(残差)を補うように学習することでモデルを強化していく。

木を深く重ねすぎると過学習のリスクがあるため、学習率(どの程度前の誤差を補正するかの割合)や木の本数などを調整しながらモデルを学習する。
予測値を求める関数は次の式で表される。
k近傍法(kNN)
k近傍法は、未知のデータと距離の近い学習データk個を抽出してラベルで多数決(回帰問題なら平均値)で未知データを予測する手法。
k近傍法は、未知のデータに最も近い(似ている)学習データを参照して予測を行うシンプルな手法である。モデルを学習するというよりも学習データをそのまま保存しておくだけに近く、未知のデータに対して以下のステップを踏んで予測を行う。

数式で表現すると回帰の場合は次のように表せる。(分類はただの多数決なので省略)
回帰問題では個の数値の平均を取るので、次の式で表される。(分類問題の場合はただの多数決なので省略)
ここで、は個のデータが含まれる近傍領域。
実装が簡単で、データの形状にあまり仮定を置かない柔軟性があるが、すべて学習データとの距離計算が必要なため、データが増えると予測に時間がかかることや、不要な特徴量があると距離の計算がノイズに影響されやすくなっていしまう。
k-means法
k-means法は、教師なし学習の代表的なクラスタリング手法である。具体的には、各クラスタの重心を計算しておき、未知のデータを最も近い重心のクラスタに割り振る手法で、学習の以下の手順で行う。

シンプルで計算効率も良いため、大量のデータのざっくりとしたグループ分けによく使われる。ただし、クラスタの数を事前に決める必要があり、データの分布によっては結果が初期値(最初のランダム割り当て)に影響されることもある。
数式での表現は反って複雑になるので省略する。
主成分分析(PCA)
主成分分析は、次元削減の代表的な手法である。とりわけデータの中に互いに相関の強い特徴がある場合に特に有効で、情報の重複を削減できる。
主成分分析では、元のデータから新しい軸(主成分)を作り出す。最初の主成分(PC1)はデータの分散を最大にとらえる方向、次の主成分(PC2)はPC1に直交しつつ次に分散が大きい方向…というように、元の特徴量の数だけ主成分を作ることができる。
各主成分が持つどれだけ情報を担っているかを寄与率と呼び、元の情報は寄与率の大きい主成分のみで表現できる。例えば、「身長-体重データ」の場合、PC1を「体格」などと解釈し、PC1のみでもある程度の情報を表現できる。

新しい軸は次の式で計算できる。
主成分分析を使うと、複数の指標をより少ない指標で説明できるようになるが、主成分は元の特徴の単純な組み合わせであるため直接の意味は分かりにくくなる(解釈が難しい)ことがある。また、標準化など前処理を適切に行わないと正しく主成分が求まらない点にも注意が必要。
パーセプトロン
パーセプトロンは、もっとも基本的な人工ニューロン(神経細胞モデル)とも言えるアルゴリズムで、いくつかの入力 から一つの出力を計算する。

数式で表現すると次のようになる。
ここで、は各入力に対する重み、は活性化関数(どのように出力するかを決める非線形な関数)である。重みパラメータを調整することで、様々な課題に対して有効なモデルを作ることができる。単純パーセプトロンの活性化関数には一般的にステップ関数が用いられる。
その他、代表的な活性化関数にはシグモイド関数やReLU関数などがある。
(1) シグモイド関数
(2) ReLU関数

ニューラルネットワーク
ニューラルネットワークは、前述のパーセプトロンを組み合わせて、より複雑なモデルにしたもの。
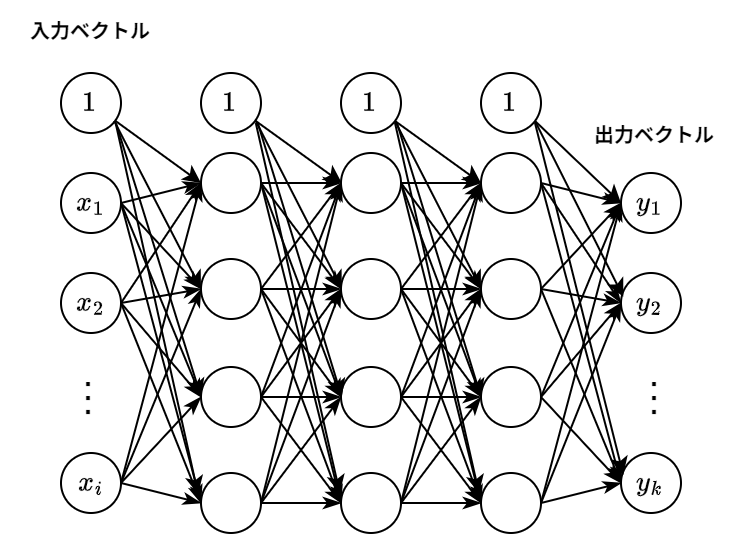
パーセプトロンとは異なり、各ノードの出力は0か1かの二値ではなく、微分可能な連続的な値を取るシグモイド関数のような活性化関数を用いる。これにより、出力が0/1のように飛び跳ねず連続的に変化するので、後述の重み調整がスムーズに行える。
※ 補足:誤差逆伝搬法について
ニューラルネットワークでは、現在のパラメータを使って予測値を計算する順伝搬と、予測値と正解値のずれからパラメータを更新する逆伝搬(誤差逆伝搬法)を交互に繰り返すことによって学習が進み、予測精度が向上していく。具体的には、ランダムな値に設定された初期パラメータからはじめて、微分計算を利用して勾配降下法に従い、正解に近い出力を返すようが重みを調整される。
